-
#8: KT_AIVLE_SCHOOL : DX_4th : 4주차 : 데이터분석KT_AIVLE_SCHOOL_DX_4th 2023. 8. 28. 22:05
8월 4주차 그리고 대망의 9월이다.
벌써 9월이라니 믿을 수 없겠지만, 8.8일부터 시작된 여정은 이제 1/6 정도를 지나왔다.
#6은 첫번째 미니 프로젝트에서 어떤 일들이 있고, 무엇을 했는지 알아보았다. (https://datawithu.tistory.com/8)
그렇다면, 이번 한 주동 안은 어떤 것을 배우고 실습을 하는지 알아보자.

짧게 브리핑을 해보자면,
지난 8월 한달 가량은 파이썬을 기초를 배웠고 그리고 드디어 이번주부터 '데이터 분석'을 하게 된다.
또한 이번 강의는 한기영 강사님과 함께 하게 되었다.
강사님은 주로 코드보다는 데이터 의미/해석에 중심을 두고 수업을 진행해주셨다.
데이터 분석 분야에서 오랜기간 실무와 강의를 하셨고,
분석을 위한 여러 툴보다는 도메인지식이 때론 해당 분야에 문제해결의 key point라고 생각하시기 때문에,
강의 기간 동안 분석에는 큰 그림이 필요하다고 강조해주셨다.
강의는
- 1. 데이터 분석 방법론
- 2. 단변량 분석: 숫자형 변수 or 범주형 변수
- 3. 이변량분석 1 : Y/Target이 숫자형 변수
- 4. 이변량 분석 2 : Y/Target이 범형 변수
- 5. 시계열 분석 : 시간에 따른 분석이 의미 있는 경우
로 나눌 수 있다.
-한 세션이 끝나면 역시... 10분간의 셀프테스트를 본다.
- 1. 데이터 분석 방법론
이번 # 8 데이터분석의 가장 핵심은 1일 차부터 5일 차까지 관통하는 데이터분석 방법론 (Crisp-Dm)이 되시겠다.
한기영 강사님은 Crisp-Dm방법론과 그에 따른 세부사항들을 어떻게 하면 비즈니스적 관점으로 녹여서 적용할 수 있는지 매번 복습 개념으로 설명해 주시곤 하셨다.
여기서 Crisp-Dm 방법론이란,
데이터 마이닝 접근방식을 설명한 가장 많이 사용되는 공개 표준 분석 모델로
Cross Industry Standard For Data Mining의 약자입니다만,
야매로저는 영어의 발음상 바삭한 요청(Crispy - Dm)이라고 외우겠습니다.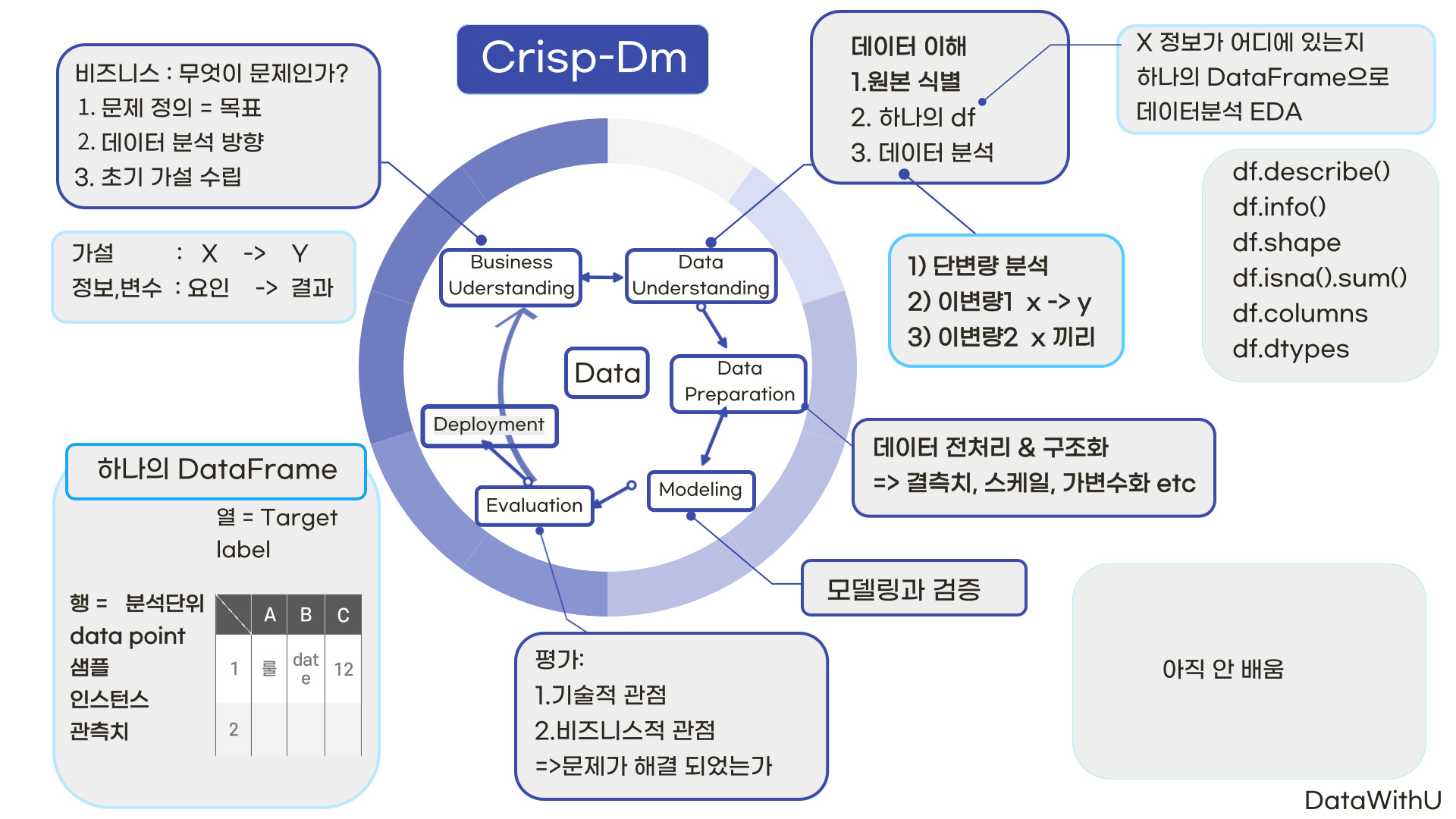
바삭한 요청 재정리 해보기 위와 같이 한 번에 표로 정리해 보면 될 것 같다.
본 t-story의 주인장은 사실상 컴맹이라 만드는 데 엄청 오랜 시간이 걸렸지만... 도움이 되었으면 하는 바람으로 정리했다.
1. 비즈니스 이해 : 가설수립
- 귀무가설 : 기존에 있던 가설
- 대립가설 : 내가 주장하고 싶은 가설/ 새로운 가설
- 가설구조 : x(y를 설명하기 위한 요인) => y(목표, 관심사, 결과)
- x y는 정보 또는 변수라고 부름
2. 데이터 이해 : 데이터원본 식별 및 취득
=> 초기 가설에서 도출된 데이터의 원본을 확인한다.
- 가용한 데이터 - 있는 데이터 => 그대로 사용 or 가공해서 사용
- 가용한데이터 - 없는 데이터 => 취득 가능 or 취득 불가능
- 이중 취득불가능한 데이터는 정보의 의미를 재정의 (정보분할, 최대한 가용한 데이터 영역으로 만들기)
3. 데이터탐색 : 기본 2차원 구조
- 통계량과 시각화
- EDA : 개별 데이터의 분포, 가설이 맞는지 파악 //NA 이상치 파악
- CDA : 애매한 정보는 통계적 분석으로 가설검증
4. 데이터 준비 : 모델링을 위한 데이터 구조를 만들기
- 개요 : 모든 셀에 값이 있어야 한다 또한 모든 값은 숫자
- (옵션) 값의 범위를 일치
- 수행되는 내용 :결측치 처리, 가변수화, 스케일링, 데이터 분할
5. 모델링
개요 : 중요변수 선택, 적절한 알고리즘 적용 예측모델 생성, 모델 평가
모델 : 데이터 안에 있는 패턴을 찾아 수학식으로 정리)
숭행 되는 내용 : 중요변수 선정, 모젤 생성, 모델 성능 검증
모델링 " 데이터로부터 패턴을 찾아, 오차를 최소 하는 패턴등,
6. 평가 (주로 오차로 평가를 한다.)
-수행 : 모델에 대한 최종평가 TEst set
비즈니스 기대가치 평가
7. 배포하기 ...
약 바삭한 요청씨를 외우셨다면, 이제 본격적으로 4.5일 동안 데이터 분석을 배우게 되는데
그전에 분석대상들에 대하여 알아야 한다.
1. 분석 (모델링) 할 수 있는 정보는
- 1). 범주형= (묶기가능) 질적 정성적 데이터 = 명목형(성별)/ 순서형(등급, 연령대)
- 2). 수치형= 양적 정량적 데이터 = 이산형(통화량, 소득 수준, 나이)/ 연속형(온도, 몸무게)-순서형은 대체로 수치형으로부터 만들어진다.
- 범주와 수치형 구분 팁을 주자면
- 1주 차 * 3배가 3주 차인가? 아니요 => 범주형 이런 방식으로 하면 유용하다.2. 분석 데이터 구조는 주로 2차원 형태로
x : feature 요인, input, 독립변수 분석단위 관측치 행 인스턴스
y : target 결과 output label 종속변수 열
위의 정보들은 칼럼 형태로 와야 좋다.보면 알겠지만, 행과 열을 나타내는 말들이 꽤 많다.
이중 강사님께서는 행 = 분석단위라는 말로 외웠으면 좋겠다고 하셨다
왜냐하면, 어떤 단위로 분석할지 문제해결을 위한 것이고 따라서 행에 어떤 단위들이 오는지에 따라
데이터 분석 방향이 달라질 수 있기 때문이다. : 시간별? 월별? 고객별?
[언제, 어떤] 그래프를 그리고 **[어떻게 해석]
3. 2차원 구조로 정리된 데이터셋을 이용하여 분석(eda, cda)
- 1) EDA 탐색적 데이터 분석 : 초기가설 => eda : 그래프, 통계량
- 2) CDA 확증적 데이터 분석 : 준비된 데이터 셋 :=> cda : 가설검정, 실험
=> 개별 변수로 분석 = 단변량 분석
=> 가설(x -> y)이 맞는지 분석 = 이변량분석 1
=> 두 Feature 간에 관계 분석 = 이변량분석 2
4. 데이터 시각화
그래프 = 시각화, 통계량 = 수치화
- 시각화 목적 : 그래프를 아름답게 꾸미는 것이 아닌, 통계적 해석을 넘어 비즈니스 인사이트를 파악하는 것
- 장점 : 한눈에 파악이 가능하지만,
- 단점 : 요약된 정보이며, 관점에 따라 해석이 달라질 수 있고 정보손실 또는 상세 데이터들을 잃어버릴 수 있다.
- 주 사용 패키지 : matplotlib & seaborn
import matplotlib.pyplot as plt
import seaborn as sns
## 미리 정리하는 구간
- 2. 단변량 분석: 숫자형 변수 or 범주형 변수
- 3. 이변량분석 1 : Y/Target이 숫자형 변수
- 4. 이변량 분석 2 : Y/Target이 범형 변수
- 5. 시계열 분석 : 시간에 따른 분석이 의미 있는 경우
이 이중 2~4까지의 내용을 총정리를 해보자면 아래처럼 정리를 해볼 수 있다.

만드는데 왜 3시간이나 걸리는 걸까.... ㅎㅎ
데이터 분석 시 의문점을 항상 가지고 있어야 한다
데이터가 그렇게 분포하고 있는 것에는 다 이유가 있다
아` 그런가 하지 말고 왜? 이건 이럴까 하고 의심하고 궁금해하는 것이 좋은 자세이다.
또한, 데이터 시각분포를 그렸다면,
- 1) 밀집되어 있는 부분 : 왜 밀집이 되어있지
- 2) 희박한 부분 : 왜 희박하지?
라는 의문을 가지고 접근해 보자
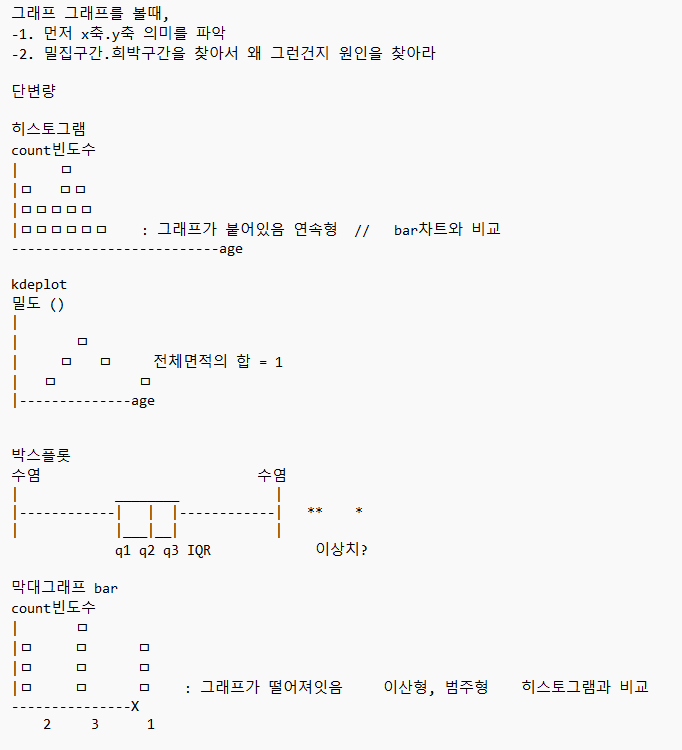
2. 단변량 분석: 숫자형 변수 or 범주형 변수
1) 단변량 분석 - 숫자형
= 개별 변수 분석
숫자형 변수는 어떻게 분석을 할까
1 > 방법 : 기초 통계량 : 숫자로 요약을 합니다 : 정보의 대푯값 : 평균/ 중앙값/최빈값/사분위수
df.describe()
df.info()
2 > 방법: 도수분포표 : 구간을 나누고 빈도수를 계산합니다 : 히스토그램
plt.hist(), sns.histplot()
- 히스토그램 팁 : bin 수가 클수록 세세하게 분포를 볼 수 있음, 값의 범위를 먼저 생각하고 개수를 나눌 것
## 시각화 : 박스플롯, 히스토그램, kdeplot
박스 플롯 : plt.boxplot(), sns.boxplot()
kdeplot : 커널 밀도 추정 함수 그래프로 히스토그램의 단점을 해결하고
확률 추정을 하기 위한 목적을 가졌으며, 그래프 아래의 면적은 1이다.
한편, 최빈값 mode()는 주로 범주형이나 이상형일 때 씁니다.
또한 평균을 사용할 시에는 과연 대푯값으로 쓸 수 있는가 를 고민해야 합니다.
1) 단변량 분석 - 범주
중요한 것은 value_counts()로 범주별 빈도수, 범주별 비율을 구하고 그래프를 그리면 된다.
- value_counts(normalize=True) 옵션 => 비율로 바꿔라
## 시각화 : sns.countplot() : 알아서 집계해서 막대그래프로 나타내줍니다.
pie 차트는 plt.pie(df.values, labels=df.index) 이런 식으로 사용해 주면 됩니다.
메모장 필기로 정리
## 이변량 분석과 가설검증
가설과 가설 검정
모집단과 표본
모든 전체 영역 일부 영역 데이터우리는 일부분으로 전체를 추정하고자 한다. = > 모집단에 대한 가설 수립
==> xy관계 " x에 따라 y 차이가 있다, x와 y과 관계가 있다
표본을 가지고 가설이 진짜 그러한지 검증/검정을 한다.# 비즈니스 이해단계에서 관심사(Y)를 도출하고 y에 영향을 주는 x요인 들어 뽑아서 초기 가설을 수립
기존 주장 : 귀무가설 Ho / 영가설.현재가설.보수가설
나의 주장 : 대립가설H1 / 근데 내가 대립가설이라고 하자마자 귀무가설이 필요하니까 그롷게 허자
#통계적 검정
-표본으로부터 대립가설을 확인하고, 모집단에서도 맞을 것이라 주장
- 차이의 값이 큰지 작은지는 어떻게 판단할 수 있을까용?? => 차이분포를 보자
- 분포 + 판단기준이 필요하다.
- 판단기준(유의수준) : 0.05(5%) 혹은 좀더 보수적인 0.01(1%)를 사용
- 보통 0.05 보다는 p-value가 작아야 차이가 있다고 판단한다.# 검정통계량
-검정(차이가 있는지 없는지 확인) 하기 위한 차이값 = (검정통계량)
t통계량, 카이제곱 통계량, f통계량
-이들은 각각 기준대비 차이로 계산됩니다.
계산된 통계량 => 각자의 분포를 가짐
분포를 통해서 그 값이(차이)가 큰지 , 작은지 판단 가능
이를 손쉽게 판단할 수 있도록 계산해 준 것이 p-value
3. 이변량분석 1 : Y/Target이 숫자형 변수
두 변수와의 관계를 살펴보기 위해, (시각화)와 (수치화)를 이용합니다.
1) x:feature가: 숫자형 변수일 때,
1. 점을 찍어서 그래프로 => 산점도
2. 각 점들이 얼마나 직선상에 모여있는지를 계산 => 공분산(covariance)/ 상관계수(correlation efficient)
3. 숫자숫자를 비교할 때 중요한 관점은 '직선(linearity)'입니다. 얼마나 직선에 가까운지!!1-1) 시각화 : 산점도
plt.scatter('x변수', 'y변수', data=df)
sns.pairplot(air, kind='reg')
1-2) 수치화 : 상관계수, 상관분석
- 눈으로 그래프의 관계파악은 어우니 관계를 숫자로 계산해서 비교
- 상관계수 Correlation coefficient : 상관계수가 유의미한 지를 검정(test) => 상관분석 /p-value
상관관계는 'r'로 표시 corRelation
-1 ~ +1 사이의 값 = 직선의 기울기와 관련,
-1 or 1에 가까울수록 강한 상관관계
상관계수끼리 비교가능
0에 가까울수록 약한 상관관계1-3) 상관계수의 유의성 검정
scipy.stats as st 모듈 사용
st.perarsonr 피어슨 상관분석 함수
-- 주의 nan이 있으면 계산이 안됨. notnull()로 계산할 것 또는. notna()
-- 결과 : ( 상관계수, p-value) 튜플로 나옴df로부터 한 번에 그리기 : df.corr()
상관계수를 heatmap으로 시각화도 가능
참고 ) 1, 직선의 기울기 2. 비선형 관계는 상관계수가 고려하지 못합니다. 오직 직선의 관계만 수치화가 가능합니다.

2) x:feature가: 범주형 변수일 때,
이때는 평균비교를 기본으로 합니다.
범주가 2개 이상일때 : 두 평균 차이를 비교
범주가 3개 이상일 때????
2-1) 시각화 : sns.barplot()을 사용합니다.

2-2) 수치화
두 평균비교 : 평균-평균 진짜 차이값으로 계산합니다
3가지 평균비교???ttest : 두 그룹 간 평균비교 / 범주 2개

anova : 전체평균과 각 그룹평균에 차이가 있는가>/ 범주가 3개 이상
범주->숫자 요약

## 평균에 대해


4. 이변량 분석 2 : Y/Target이 범주형 변수
1) x:feature가: 범주형 변수일 때,
이변량분석 2에서 중요한 것은 집계표가 있어야 한다는 것!!
1-1) Crosstab 교차로로 집계를 해야 합니다 => 교차표로 시각화 :mosaic plot
=> 가설검증 : chi-squared testpd.crosstab(X정보, Y정보, normalize= ) 옵션 normalize= colulmlns/index/all
1-2) 시각화
mosaic(df, [x축 칼럼, y축 칼럼])
plt.axhline()
mosaic plot은 범주별 양과 비율을 그래프로 나타내니다.
내부에서 알아서 교차표를 만들고 비율을 비교합니다.1-3) 수치화 : 카이제곱 검정
1. 확률적으로 독립일 때 기대되는 값 = 아무런`관련이 없을 때
2. 관측된 값이 둘의 차이가 카이제곱 통계량입니다.

2) X가 숫자형 변수일 때,

5. 시계열 분석 : 시간에 따른 분석이 의미 있는 경우
그렇다면 시계열 분석은 왜 나왔는가??

1.(시계열 데이터 = 시간의 흐름에 따른 패턴) 파악 방법 3가지 종류- 1). y의 변화에 초첨이 있다 예) 주가
모델링 : 통계적 시계열 모델링 :SARIMAX s arima x
- 2). 시간에 흐르는 정보를 열데이터로 붙여서 분석
y, xi에 있는 흐름을 feature로 생성
예) 최근 7일간 평균온도
모델링 : ML알고리즘
- 3). 딥러닝에서 쓰는 방법 : 방법 1&방법 2를 조합
y, xi에 있는 흐름을 NeuralNet이 알아서 추출
모델링 : 딥러닝의 LSTM, CNN, RNN방식
2. 시계열 데이터의 두 가지 어려움- 시계열 데이터는 시간/시기를 고려해야 함
어느 기간? 반복되는 주기?
- 전날 숫자가 다음날 숫자에 영향을?3. 기존 분석방법을 적용할 시의 문제점
3-1) 시계열 : 단별량-숫자
박스플롯이나, 히스토그램으로는 파악하기 어려운 경우가 많음
( 그 시간의 이벤트를 반영되지 않음)
3-2) 시계열 : 숫자-숫자
산점도 : 완전직선으로 나옴
상관계수는 거의 1, p도 거의 0
#3-3) 시계열 : 범주-숫자
요일별로 주가가 달라지나? 아무 관련이 없어 보임
/사실 관련이 있는데!!/4. 시계열 데이터 분석 방법
시각화 :시간에 흐름에 따른 y를 의 추세/패턴을 보고 싶음
- 라인차트 :이때 x축은 시간축이다.
- 시계열데이터 분해

- 자기상관성
5. 시계열에서 패턴을 찾으면 데이터로 바꿀 수 있어야 한다.

'KT_AIVLE_SCHOOL_DX_4th' 카테고리의 다른 글
#10: KT_AIVLE_SCHOOL : DX_4th : 5주차 : 미니 프로젝트 2차 (1) 2023.09.11 #9: KT_AIVLE_SCHOOL : DX_4th : 5주차 : 데이터 수집 (2) 2023.09.04 #7: KT_AIVLE_SCHOOL : DX_4th : 기자단이 되다. (1) 2023.08.28 #6: KT_AIVLE_SCHOOL : DX_4th : 3주차 : 미니프로젝트1 : 팀프로젝트 (0) 2023.08.26 #5: KT_AIVLE_SCHOOL : DX_4th : 2주차 : 데이터 다듬기 (0) 2023.08.26